Browser Automation Comparison
Two benchmark suites measuring OpenBrowser against competitors:- CLI Benchmark (2026-03-15) — 4-way comparison of CLI tools driven by an LLM via a single Bash tool
- MCP Benchmark (below) — 3-way comparison of MCP servers as tool providers
MCP Server Comparison
Benchmark date: 2026-02-21 | OpenBrowser MCP v0.1.26 (CodeAgent, 1 tool) | Playwright MCP (latest) | Chrome DevTools MCP (latest)Overview
Three approaches to browser automation via MCP, measured on identical tasks.| Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP | |
|---|---|---|---|
| Maintainer | Microsoft | Chrome DevTools team (Google) | OpenBrowser |
| GitHub Stars | 27,400+ | 26,200+ | — |
| Engine | Playwright (Chromium/Firefox/WebKit) | Puppeteer (CDP) | Raw CDP (direct) |
| Tools | 22 core (34 total) | 26 | 1 (execute_code) |
| Approach | A11y snapshot with every action | A11y snapshot on demand | CodeAgent — Python code execution with browser namespace |
| Element IDs | ref from snapshot ([ref=e25]) | uid from snapshot (uid=1_2) | Numeric index from state |
| Transport | stdio | stdio | stdio |
| Language | TypeScript (Node.js) | TypeScript (Node.js) | Python |
Token Usage Benchmark
Methodology
All three MCP servers were started as subprocesses and tested via JSON-RPC stdio transport. Same 5-step workflow, same pages, same measurement method. All numbers are real measurements, not estimates. Workflow: Navigate to Wikipedia Python page -> get page state -> click link -> go back -> get state again.Results: 5-Step Workflow on Wikipedia (Complex Page)
| Metric | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Tool calls | 5 | 5 | 5 |
| Total response chars | 992,065 | 539,209 | 1,131 |
| Est. response tokens | 248,016 | 134,802 | 283 |
| Token ratio vs OpenBrowser | 877x more | 476x more | 1x (baseline) |
Results: Small Page (httpbin.org/forms/post)
| Operation | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Navigate | 1,985 chars | 182 chars | 105 chars |
| Page state | 1,896 chars | 1,366 chars | 1,488 chars |
| Type/fill | 526 chars | 95 chars | 92 chars |
| List tabs/pages | 367 chars | 120 chars | 195 chars |
Per-Operation Token Breakdown (Wikipedia)
| Operation | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Navigate | 495,950 chars (~124K tokens) | 240 chars (~60 tokens) | 134 chars (~34 tokens) |
| Snapshot / Get state | 495,437 chars (~124K tokens) | 538,467 chars (~135K tokens) | 421 chars (~105 tokens) |
| Click | 341 chars (~85 tokens) | 218 chars (~55 tokens) | 80 chars (~20 tokens) |
| Go back | 198 chars (~50 tokens) | 149 chars (~37 tokens) | 75 chars (~19 tokens) |
| Get state (2nd) | 139 chars (~35 tokens) | 135 chars (~34 tokens) | 421 chars (~105 tokens) |
Why the Difference
| Design Decision | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Navigate response | Full a11y snapshot | URL confirmation | URL confirmation |
| State query | Always full snapshot | Full a11y snapshot (take_snapshot) | Compact (105 tokens) or full |
| Click response | Updated snapshot | Action confirmation | Action confirmation |
| Text extraction | No dedicated tool | No dedicated tool | evaluate() + Python processing |
| Content search | Dump full snapshot | evaluate_script (JS) | evaluate() + Python regex/string matching |
| Element search | Part of snapshot | uid from snapshot | browser.get_browser_state_summary() |
take_snapshot to see the page (~135K tokens for Wikipedia). One snapshot is comparable in size to Playwright’s, but actions don’t auto-return snapshots.
OpenBrowser MCP: Actions return minimal confirmations. The agent explicitly requests the level of detail it needs — from 105 tokens (compact state) to 3,981 tokens (targeted search) to 25,164 tokens (full page text). More tool calls, dramatically fewer tokens.
What Each Server Returns (Verbatim)
All responses below are real output captured from each MCP server on the httpbin.org/forms/post page.Navigate
Playwright MCP — returns full a11y snapshot with every navigation (~2,150 chars on httpbin, ~496K chars on Wikipedia):Get Page State / Snapshot
Playwright MCPbrowser_snapshot — full a11y tree again (~1,896 chars on httpbin, ~495K chars on Wikipedia):
take_snapshot — full a11y tree (~1,214 chars on httpbin, ~538K chars on Wikipedia):
Click / Type / Go Back
All three servers return short confirmations for actions:| Operation | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Click | Clicked element | Clicked element uid=1_2 | Clicked element 5 |
| Type | Updated snapshot (~526 chars) | Filled element uid=1_2 | Typed 'John Doe' into element 4 |
| Go back | ~198 chars | ~149 chars | Navigated back |
Targeted Extraction (OpenBrowser only)
No equivalent in Playwright or Chrome DevTools MCP — both require dumping the full snapshot or running JavaScript from the client side. Element search — the LLM writes Python to find specific elements:| Server | Method | Response Size |
|---|---|---|
| Playwright MCP | browser_snapshot (dump full tree, search client-side) | ~495K chars |
| Chrome DevTools MCP | take_snapshot (dump full tree, search client-side) | ~538K chars |
| OpenBrowser MCP | evaluate() + Python string matching | ~900 chars |
Cost Comparison
MCP tool response costs per 5-step workflow on a complex page (Wikipedia). These tokens are added to the LLM’s context window, charged at input token rates. All numbers based on real measurements.| Model | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Claude Sonnet 4.6 ($3/M input) | $0.744 | $0.404 | $0.001 |
| Claude Opus 4.6 ($5/M input) | $1.240 | $0.674 | $0.001 |
| GPT-5.2 ($1.75/M input) | $0.434 | $0.236 | $0.001 |
| Model | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Claude Sonnet 4.6 | $744 | $404 | $0.85 |
| Claude Opus 4.6 | $1,240 | $674 | $1.42 |
| GPT-5.2 | $434 | $236 | $0.50 |
E2E LLM Benchmark
Methodology
Six real-world browser tasks run through Claude Sonnet 4.6 on AWS Bedrock (Converse API). Each task uses a single MCP server as tool provider. The LLM decides which tools to call and when the task is complete. All tasks run against live websites. Tasks: Wikipedia fact lookup, httpbin form fill, Hacker News data extraction, Wikipedia search + navigation, GitHub release lookup, example.com content analysis.Results: Task Success
All three servers pass all 6 tasks.| Task | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| fact_lookup | PASS | PASS | PASS |
| form_fill | PASS | PASS | PASS |
| multi_page_extract | PASS | PASS | PASS |
| search_navigate | PASS | PASS | PASS |
| deep_navigation | PASS | PASS | PASS |
| content_analysis | PASS | PASS | PASS |
| Total | 6/6 | 6/6 | 6/6 |
Results: Tool Calls and Duration
| Metric | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
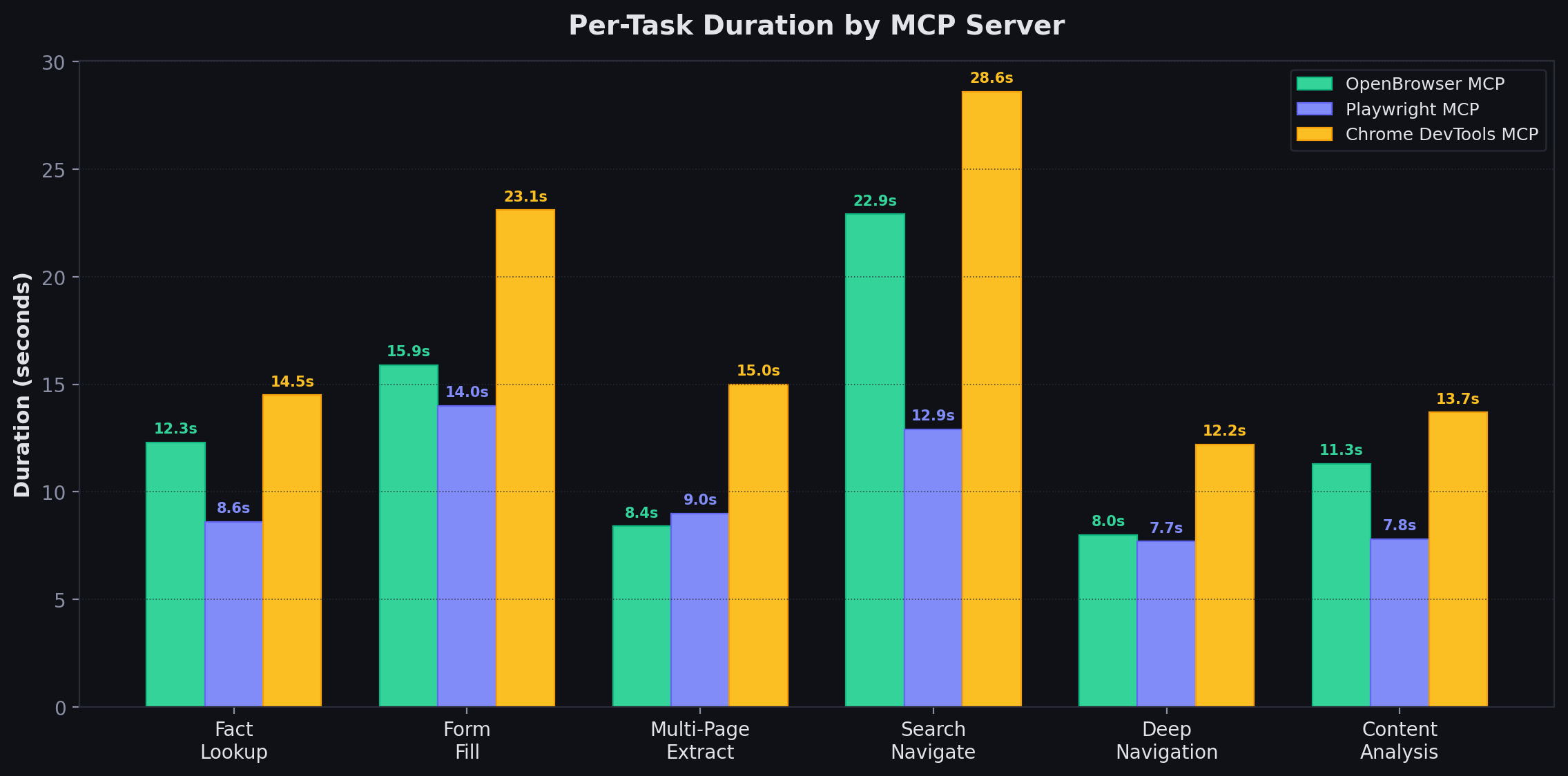
| Total tool calls (mean) | 9.4 | 19.4 | 13.8 |
| Avg tool calls/task | 1.6 | 3.2 | 2.3 |
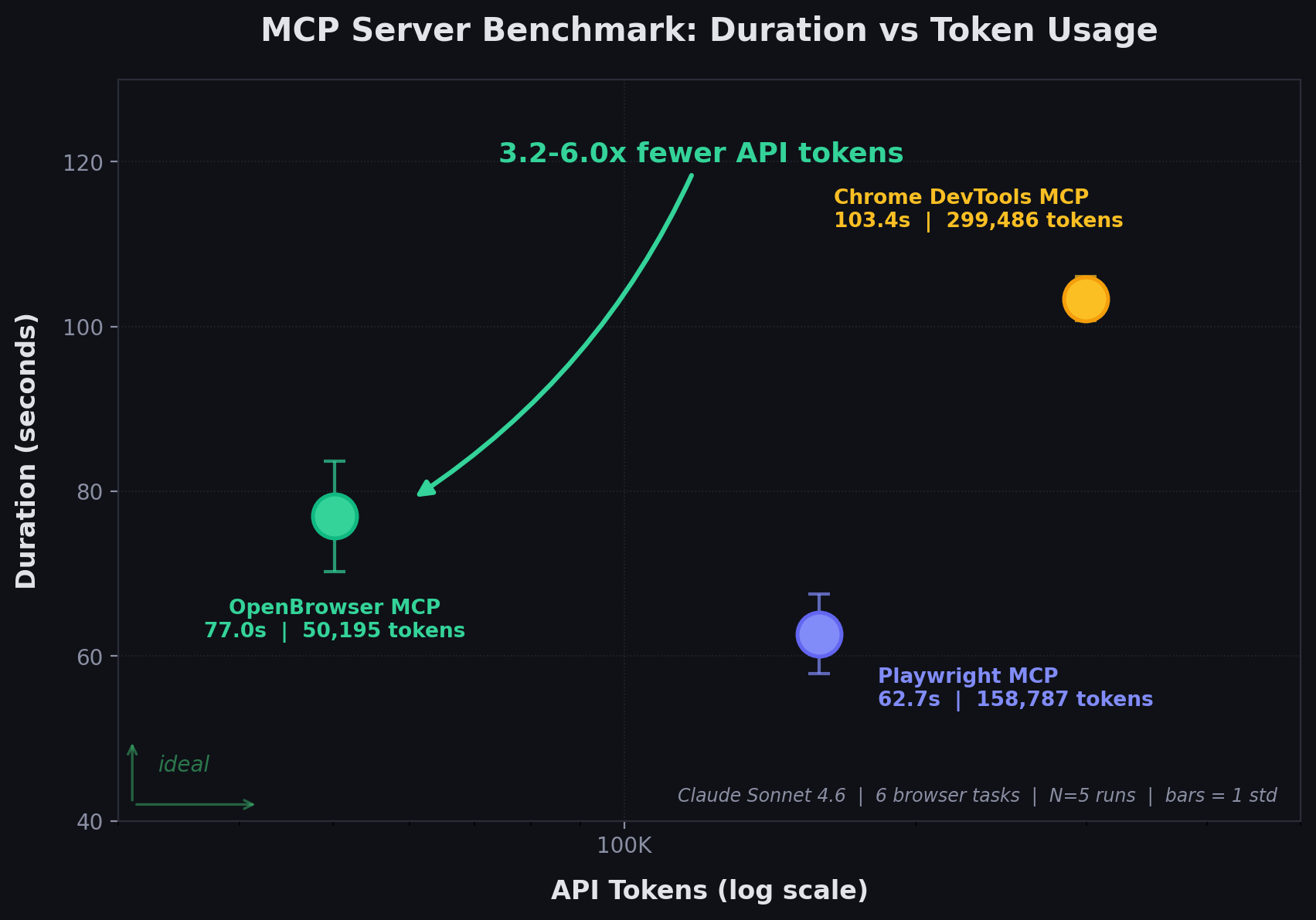
| Total duration (mean +/- std) | 62.7 +/- 4.8s | 103.4 +/- 2.7s | 77.0 +/- 6.7s |
Per-Task Duration
Per-Task Tool Calls

Results: Token Efficiency
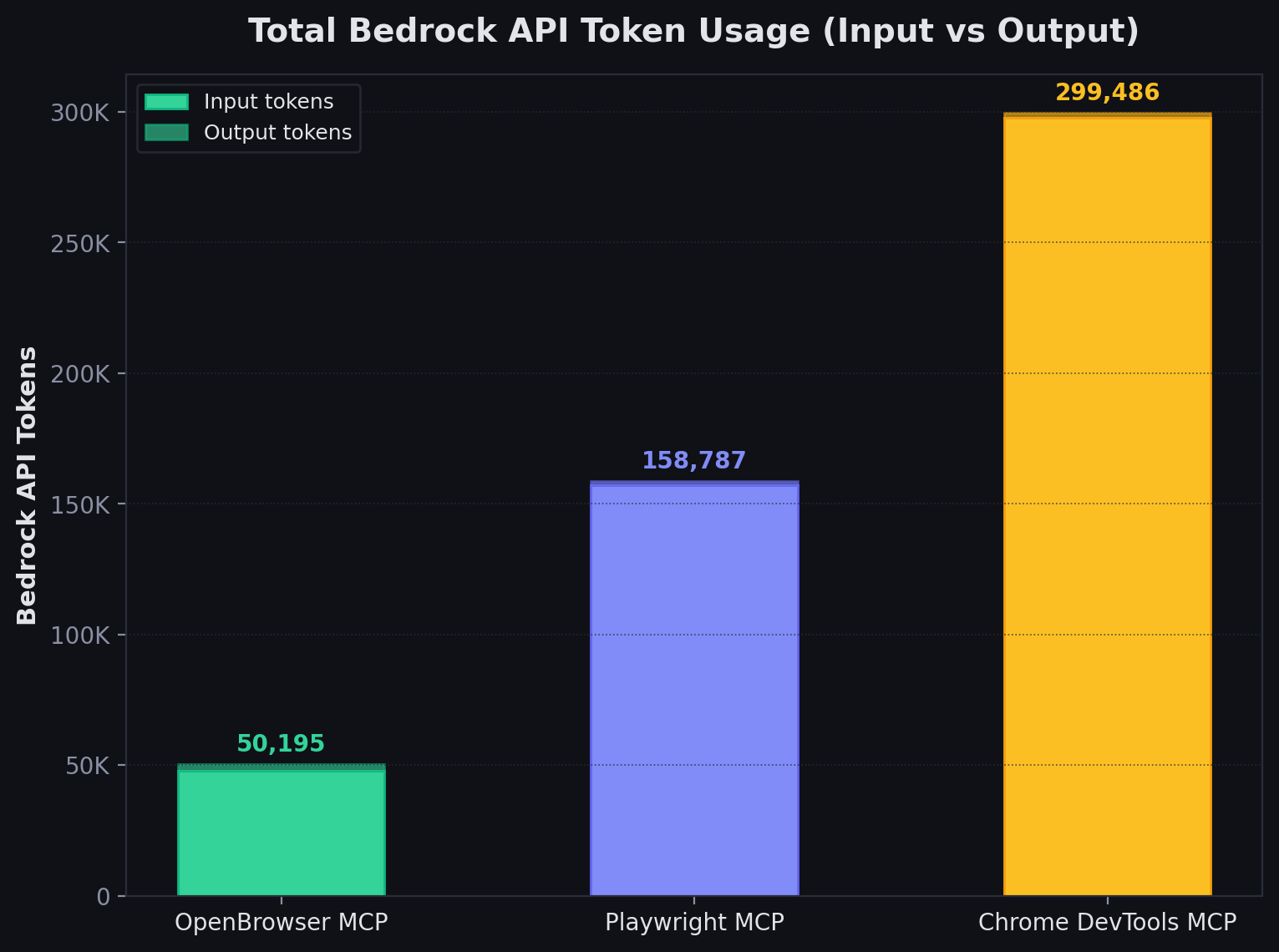
Bedrock API token usage measured from the Converse APIusage field (mean across 5 runs, 10,000-sample bootstrap CIs).
| Metric | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Bedrock API Tokens (mean) | 158,787 | 299,486 | 50,195 |
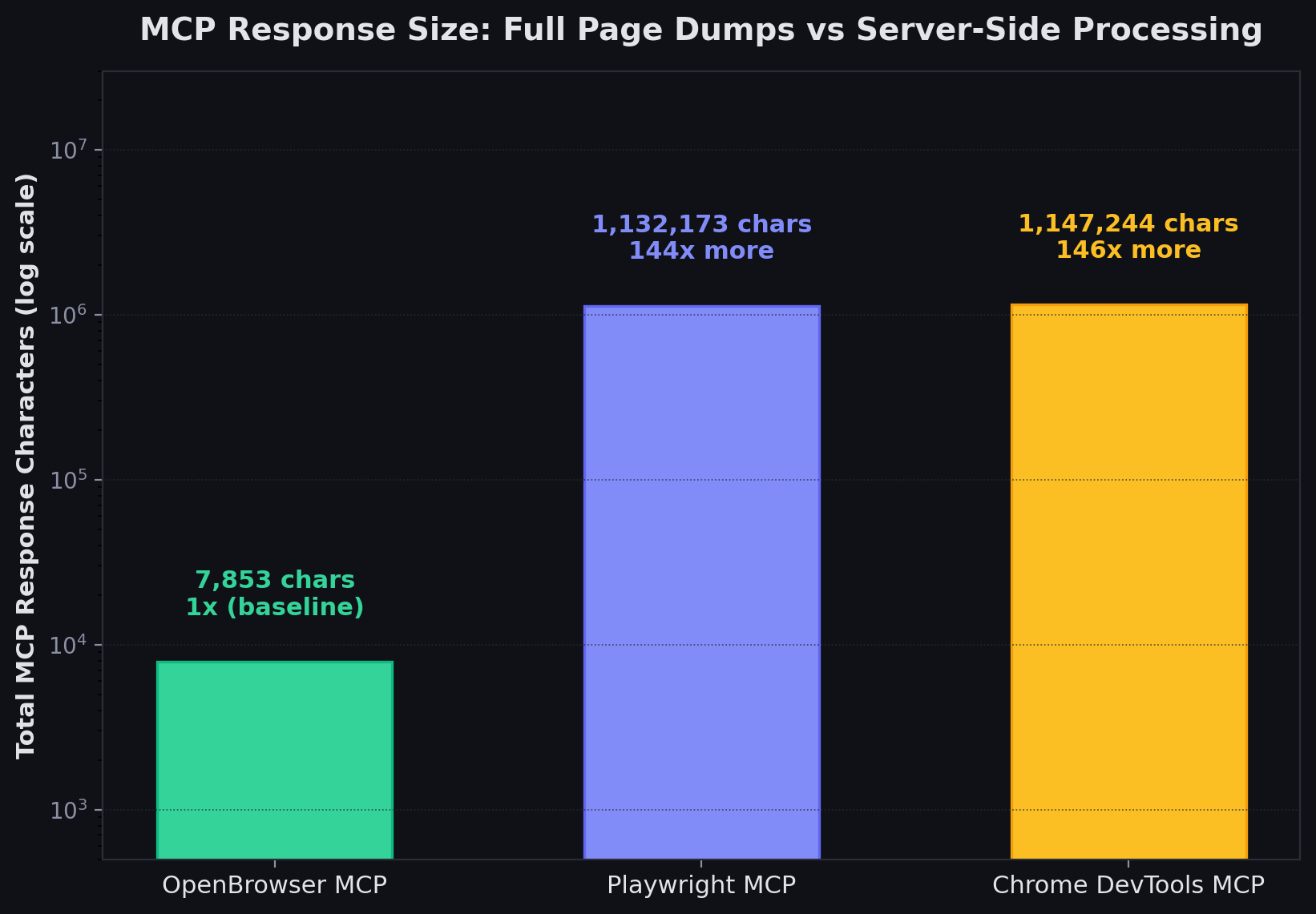
| MCP Response Chars (mean) | 1,132,173 | 1,147,244 | 7,853 |
| API Token ratio vs OpenBrowser | 3.2x more | 6.0x more | 1x (baseline) |
| Response char ratio vs OpenBrowser | 144x more | 146x more | 1x (baseline) |
Per-Task MCP Response Size
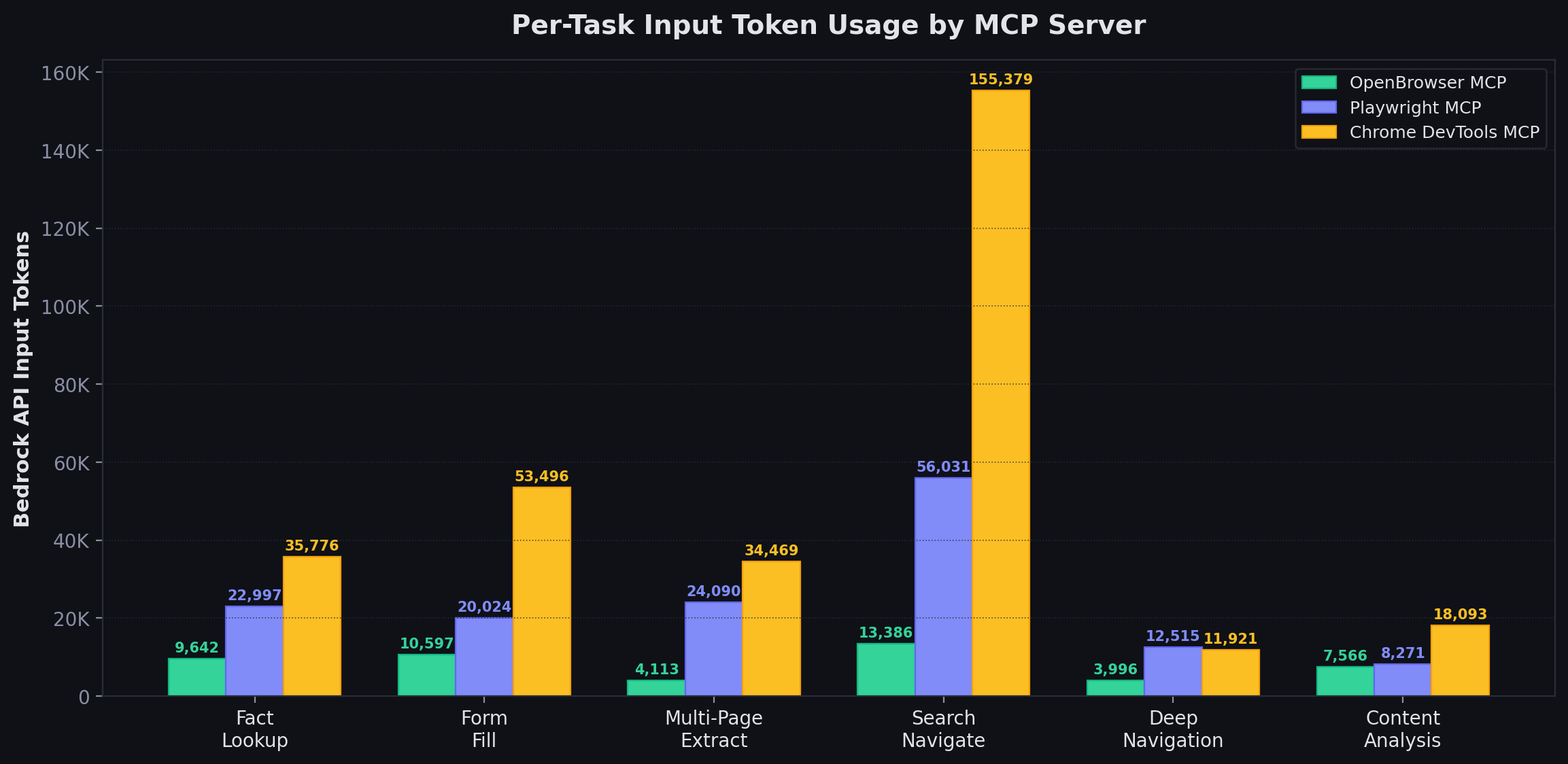
| Task | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| fact_lookup | 520,742 chars | 509,058 chars | 3,144 chars |
| form_fill | 4,075 chars | 3,150 chars | 2,305 chars |
| multi_page_extract | 58,392 chars | 38,880 chars | 294 chars |
| search_navigate | 519,241 chars | 595,590 chars | 2,848 chars |
| deep_navigation | 14,875 chars | 195 chars | 113 chars |
| content_analysis | 485 chars | 501 chars | 499 chars |
Per-Task Input Token Usage
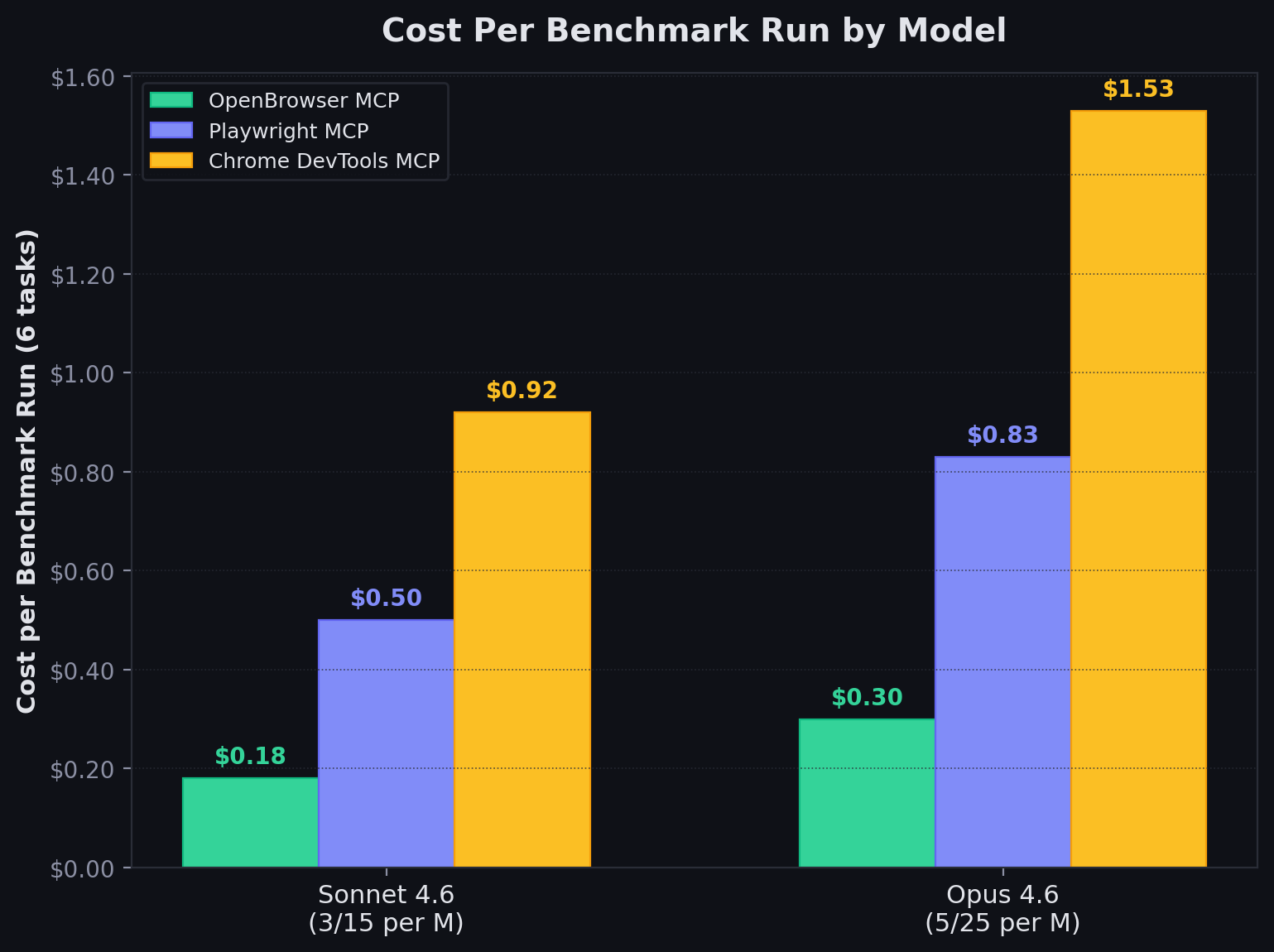
Results: Cost Per Benchmark Run (6 Tasks)
Cost per benchmark run based on Bedrock API token usage (input + output tokens at respective rates).| Model | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Claude Sonnet 4.6 (15 per M) | $0.50 | $0.92 | $0.18 |
| Claude Opus 4.6 (25 per M) | $0.83 | $1.53 | $0.30 |
Why OpenBrowser Uses More Tool Calls but Fewer Tokens
Playwright sends the full page with every response, so the LLM gets the answer immediately but pays for ~120K tokens per Wikipedia page load. OpenBrowser returns compact results (~30-800 chars per call), so the LLM needs more round-trips to navigate and extract but pays far fewer tokens overall. For a single simple task, Playwright’s approach is fast. At scale (thousands of workflows, complex pages, multi-step agents), the MCP response size difference is 144x.Tool Surface Comparison
Playwright MCP (22 core tools, 34 total)
Navigation, interaction, form filling, file upload, drag and drop, hover, key press, select option, screenshots, snapshots, console messages, dialog handling, network requests, tab management, code execution, PDF export, wait conditions, resize, vision-mode coordinate tools, test assertions.Chrome DevTools MCP (26 tools)
Input automation (click, drag, fill, fill_form, hover, press_key, handle_dialog, upload_file), navigation (navigate_page, new_page, close_page, list_pages, select_page, wait_for), emulation (emulate, resize_page), performance tracing (start/stop/analyze), network debugging (list/get requests), JS execution, console messages, screenshots, DOM snapshots.OpenBrowser MCP (1 tool — CodeAgent)
| Tool | Capabilities |
|---|---|
execute_code | Python code execution in a persistent namespace with browser automation functions: navigate(), click(), input_text(), scroll(), go_back(), select_dropdown(), send_keys(), upload_file(), evaluate() (JS), switch()/close() (tabs), done() (task completion). Also provides file_system for local file operations and pre-imported libraries (json, pandas, re, csv, etc.) |
Unique to OpenBrowser
Features no competitor offers:- CodeAgent architecture — single
execute_codetool runs Python in a persistent namespace. The LLM writes code to navigate, extract, and process data rather than calling individual tools. Variables and state persist between calls. - 144x smaller MCP responses — returns only the data the code explicitly extracts, not full page dumps
- JS evaluation with Python processing —
await evaluate("JS expression")returns Python objects directly (dicts, lists, strings), enabling pandas/regex/json processing in the same code block - Built-in libraries — json, pandas, numpy, matplotlib, csv, re, datetime, requests, BeautifulSoup available in the execution namespace
- File system access —
file_systemobject for reading/writing local files from browser automation code - Dropdown support —
select_dropdown()anddropdown_options()for native<select>elements - Task completion signal —
done(text, success)to explicitly mark task completion with a result
Gaps vs Competitors
| Capability | Playwright MCP | Chrome DevTools MCP | OpenBrowser MCP |
|---|---|---|---|
| Cross-browser | Yes (Chromium/Firefox/WebKit) | No | No |
| Screenshots | Yes | Yes | No |
| File upload | Yes | Yes | No |
| PDF export | Yes | No | No |
| Network monitoring | Yes | Yes | No |
| Console logs | Yes | Yes | No |
| Performance tracing | No | Yes | No |
| Emulation (device/viewport) | No | Yes | No |
| Drag and drop | Yes | Yes | No |
| Dialog handling | Yes | Yes | No |
| Wait conditions | Yes | Yes | No |
| Code generation | Yes | No | No |
| Incremental snapshots | Yes | No | No |
| Accessibility tree | Via snapshot | Via snapshot | Via evaluate() JS queries |
| Content grep/search | No | No | Via evaluate() + Python |
| Progressive disclosure | No | No | Yes (code extracts only what’s needed) |
| Session reuse | No | Puppeteer-managed | Yes (existing Chrome) |
Benchmark Methodology Notes
Token Usage Benchmark (5-step workflow)
- All three servers benchmarked via JSON-RPC stdio subprocess — no estimates
- Response sizes measured as total JSON-RPC response character count
- Estimated tokens = characters / 4 (standard approximation for mixed English/JSON)
- 5-step workflow uses matched operations: navigate, get state/snapshot, click, go back, get state/snapshot
- Raw benchmark data:
benchmarks/playwright_results.json,benchmarks/cdp_results.json,benchmarks/openbrowser_results.json
E2E LLM Benchmark (6 real-world tasks, N=5 runs)
- Model: Claude Sonnet 4.6 on AWS Bedrock (Converse API)
- Each task uses a single MCP server as tool provider via JSON-RPC stdio
- The LLM autonomously decides which tools to call and when the task is complete
- 5 runs per server, 10,000-sample bootstrap for 95% confidence intervals
- 6 tasks: fact_lookup, form_fill, multi_page_extract, search_navigate, deep_navigation, content_analysis
- All tasks run against live websites (Wikipedia, httpbin.org, news.ycombinator.com, github.com, example.com)
- Bedrock API token usage measured from the Converse API
usagefield (actual billed tokens) - MCP response sizes measured from tool response character counts
- Playwright MCP tested via
npx @playwright/mcp@latest - Chrome DevTools MCP tested via
npx -y chrome-devtools-mcp@latest - OpenBrowser MCP v0.1.26 tested via
uvx openbrowser-ai[mcp]==0.1.26 --mcp - All tests run on macOS, M-series Apple Silicon
- Benchmark scripts:
benchmarks/e2e_llm_benchmark.py,benchmarks/e2e_llm_stats.py - Results:
benchmarks/e2e_llm_stats_results.json